Een firma verkoopt dozen fruitsap met in de reclame de boodschap dat elke doos gemiddeld 10 gram suiker per 100 ml bevat.
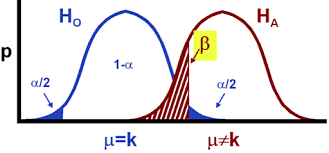
Neem als uitgangspunt de hypothese dat het de bedoeling is van de verkoper om koopwaar met het juiste gehalte suiker te leveren. Het is aan te raden de geleverde partij te controleren, d.w.z. te toetsen aan de gestelde eisen. We formuleren de volgende hypothesen:  tegen
tegen 
Het is mogelijk dat onze beslissingsregel de geleverde koopwaar afkeurt terwijl ze juist is. De fout die we dan begaan is type I-fout of een  -fout. De verkoper loopt door deze beslissingsregel een risico dat een goede partij ten onrechte afgekeurd wordt. Vandaar dat een type -fout het risico van de verkoper is.
-fout. De verkoper loopt door deze beslissingsregel een risico dat een goede partij ten onrechte afgekeurd wordt. Vandaar dat een type -fout het risico van de verkoper is.
We houden onze beslissingsregel vast. De geleverde partij heeft echter een gemiddelde hoeveelheid suiker dat verschilt van 10 gram. Een steekproef uit deze slechte partij kan echter een waarde voor het steekproefgemiddelde geven dat toch in het aanvaardingsgebied ligt. Dit impliceert dat we de geleverde koopwaar aanvaarden terwijl ze verkeerd is. De fout die we dan begaan is een type II-fout of een  – fout. De koper loopt door deze beslissingsregel een risico die slechte partij te aanvaarden. We spreken van het risico van de koper.
– fout. De koper loopt door deze beslissingsregel een risico die slechte partij te aanvaarden. We spreken van het risico van de koper.


 . Een student die blindelings gokt, heeft in dit evaluatiesysteem toch een positieve score. Om het gokken tegen te gaan zal men c punten aftrekken bij een fout antwoord. We bepalen de waarde van c zodat de student noch een positieve, noch een negatieve gemiddelde score zal hebben. Met andere woorden:
. Een student die blindelings gokt, heeft in dit evaluatiesysteem toch een positieve score. Om het gokken tegen te gaan zal men c punten aftrekken bij een fout antwoord. We bepalen de waarde van c zodat de student noch een positieve, noch een negatieve gemiddelde score zal hebben. Met andere woorden:  .
. en dus is
en dus is  . We trekken dus
. We trekken dus  punt af bij een fout antwoord.
punt af bij een fout antwoord. punten af
punten af oplossen. De meest wiskundige manier is op zoek gaan naar een primitieve functie F(x) van f(x) en dan is
oplossen. De meest wiskundige manier is op zoek gaan naar een primitieve functie F(x) van f(x) en dan is  . Maar soms is het berekenen van een primitieve functie een zeer lastige of onmogelijke taak. Is het in die gevallen dan onmogelijk om de bepaalde integraal te berekenen?
. Maar soms is het berekenen van een primitieve functie een zeer lastige of onmogelijke taak. Is het in die gevallen dan onmogelijk om de bepaalde integraal te berekenen?
![[a,b]](https://usercontent.one/wp/www.wiskundemagie.be/wp-content/ql-cache/quicklatex.com-611c86eb16b0fb9954e2532a2f68b269_l3.png?media=1678572382 "Rendered by QuickLaTeX.com") in een even ,n , aantal stukken en stel
in een even ,n , aantal stukken en stel  .
. .
.![\int_a^b f(x)\ dx \approx \frac{h}{3}\Big [ f(a)+f(b)+4\Big(f(a+h)+f(a+3h)+\cdots+f(a+(n-1)h\Big)+2\Big(f(a+2h)+f(a+4h)+\cdots+f(a+(n-2)h)\Big)\Big]](https://usercontent.one/wp/www.wiskundemagie.be/wp-content/ql-cache/quicklatex.com-f59df2699267624b400f73f5e7ba56e1_l3.png?media=1678572382 "Rendered by QuickLaTeX.com")
 over
over  ,
, en
en  .
.

 , dan us
, dan us  en kunnen we de bepaalde integraal benaderen door
en kunnen we de bepaalde integraal benaderen door 
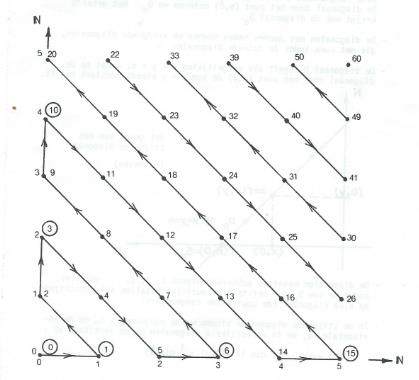
 aftelbaar oneindig is, moeten we een bijectie opstellen tussen
aftelbaar oneindig is, moeten we een bijectie opstellen tussen  . We kunnen dit doen via de diagonaalmethode van Cantor :
. We kunnen dit doen via de diagonaalmethode van Cantor :
 :
: ![\[f(x,y)=\dfrac{1}{2}((x+y)^2+2(x+y)+(-1)^{x-y})\]](https://usercontent.one/wp/www.wiskundemagie.be/wp-content/ql-cache/quicklatex.com-ce97af6234a2dbfb8497ac98b37f12e8_l3.png?media=1678572382 "Rendered by QuickLaTeX.com")
 van de eerste n natuurlijke getallen zal verschijnen op elke diagonaal ( de omcirkelde rangnummers) .
van de eerste n natuurlijke getallen zal verschijnen op elke diagonaal ( de omcirkelde rangnummers) . van de positieve wortel van de vierkantsvergelijking
van de positieve wortel van de vierkantsvergelijking  .
. en
en  .
. en
en  .
. heeft bij benadering als oplossingen -8,52 en 7,52. Dus is
heeft bij benadering als oplossingen -8,52 en 7,52. Dus is  . Het corresponderend punt in het vlak is
. Het corresponderend punt in het vlak is  .
. heeft bij benadering als oplossingen -9,23 en 8,23 zodat
heeft bij benadering als oplossingen -9,23 en 8,23 zodat  . Het corresponderend punt in het vlak is
. Het corresponderend punt in het vlak is 
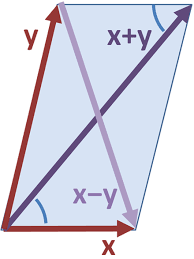
 is de Euclidische afstand, gedefinieerd door
is de Euclidische afstand, gedefinieerd door ![\[ d(x,y)=\sqrt{(x_2-x_1)^2+(y_2-y_1)^2}\]](https://usercontent.one/wp/www.wiskundemagie.be/wp-content/ql-cache/quicklatex.com-211ef7c9e2fa63f9588f8a4fe0b81f46_l3.png?media=1678572382 "Rendered by QuickLaTeX.com")
![\[\Vert x\Vert =\sqrt{x_1^2+y_1^2}\]](https://usercontent.one/wp/www.wiskundemagie.be/wp-content/ql-cache/quicklatex.com-73eca24c78f884062f589cf453b9568f_l3.png?media=1678572382 "Rendered by QuickLaTeX.com")
![\[d(x,y)=\Vert y-x\Vert\]](https://usercontent.one/wp/www.wiskundemagie.be/wp-content/ql-cache/quicklatex.com-de12751528934865b0dcceba582f9c96_l3.png?media=1678572382 "Rendered by QuickLaTeX.com")
![\[x.y=x_1x_2+y_1y_2\]](https://usercontent.one/wp/www.wiskundemagie.be/wp-content/ql-cache/quicklatex.com-f18f22cbea261fffec22d96aec5907dc_l3.png?media=1678572382 "Rendered by QuickLaTeX.com")
 en
en  .
.

 . Maar dat is niet altijd zo. Er zijn metrieken waarmee geen skalair product is geassocieerd. Een voorbeeld is de Manhattan metriek
. Maar dat is niet altijd zo. Er zijn metrieken waarmee geen skalair product is geassocieerd. Een voorbeeld is de Manhattan metriek ![\[d(x,y)=|x_2-x_1|+|y_2-y_1|\]](https://usercontent.one/wp/www.wiskundemagie.be/wp-content/ql-cache/quicklatex.com-3eb0c22b8fda36e4c5023afbc60c9a2b_l3.png?media=1678572382 "Rendered by QuickLaTeX.com")
![\[\Vert x+y \Vert +\Vert x-y \Vert=2(\Vert x \Vert+ \Vert y\Vert)\]](https://usercontent.one/wp/www.wiskundemagie.be/wp-content/ql-cache/quicklatex.com-0453353651a27b55a769ded2e344ea20_l3.png?media=1678572382 "Rendered by QuickLaTeX.com")